ARTICLE: THE POWER OF AI IN STREAMLINING CONFIGURATION ITEM IDENTIFICATION
At digitalsalt we are in the business of turning complex processes into manageable tasks. Our team of experienced specialists and consultants brings together knowledge from various fields, including software development, data analytics, and integrated logistics support. We are not constrained by borders, and we are always ready to tackle the next challenge.
One such challenge was a recent project that involved identifying Configuration Items (CIs) in a large Bill of Materials (BoM) with over 60,000 positions. The task was complex, but we saw it as an opportunity to demonstrate the power of Artificial Intelligence (AI) in streamlining such processes.

Image created with the assistance of AI-based image synthesis

Inaccurate and time-consuming manual process
Our client faced a challenge in identifying Configuration Items (CIs) in a large Bill of Materials (BoM) with over 60,000 positions. The task was complex and threatened to lead to inaccuracies and inefficiencies, high costs of time and resources, and potentially critical errors.
Implement Machine-Learning Approach
digitalsalt provided a comprehensive Machine Learning Lifecycle approach to tackle this challenge. This involved target identification, data collection, cleansing, processing, exploratory data analysis, model training, testing, parameter tuning, feature engineering, model evaluation, optimization and deployment.


Benefit from 98% Accuracy
The machine learning model was able to accurately identify CIs and non-CIs in a large BoM with an impressive accuracy of 98%. This not only saved time and reduced errors but also provided valuable insights that can drive decision-making.
If you are interested in the details of how we achieved this, continue reading.
The Challenge: Configuration Items and Bill of Materials
A Configuration Item (CI) is any hardware, software, or combination of both that satisfies an end-use function and is designated for separate Configuration Management. Identifying a CI involves considering whether it could…
- compromise safety if a failure occurs,
- cause complete failure of the platform/system,
- incorporates specially developed software or firmware not managed as part of a Hardware Configuration Item (HWCI),
- interfaces with other platforms, systems, or equipment,
- or incorporates performance specifications and testing requirements.
On the other hand, a Bill of Materials (BoM) is a comprehensive list of parts, items, assemblies, and other materials required to create a product, providing a detailed breakdown of what is needed and the quantities of each component.
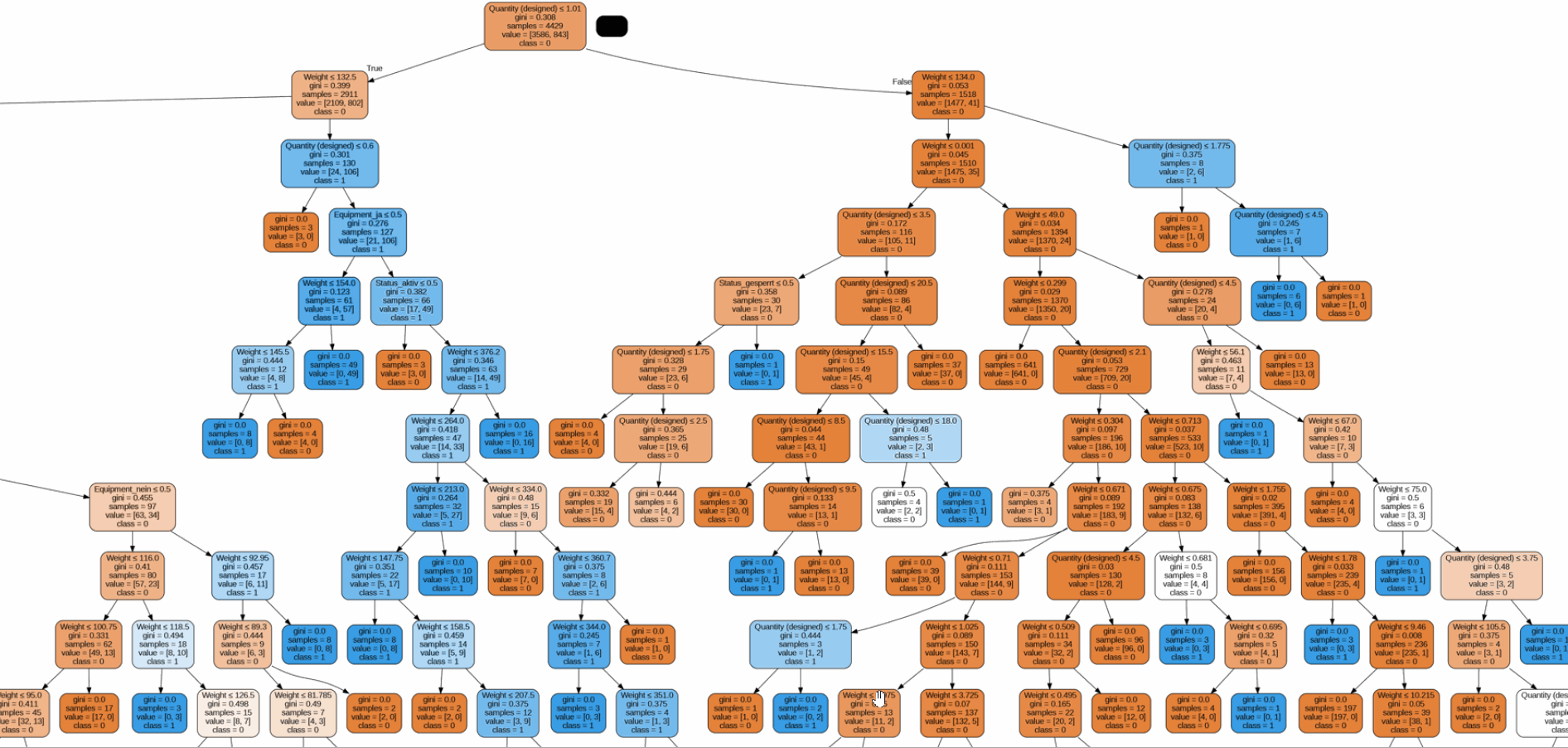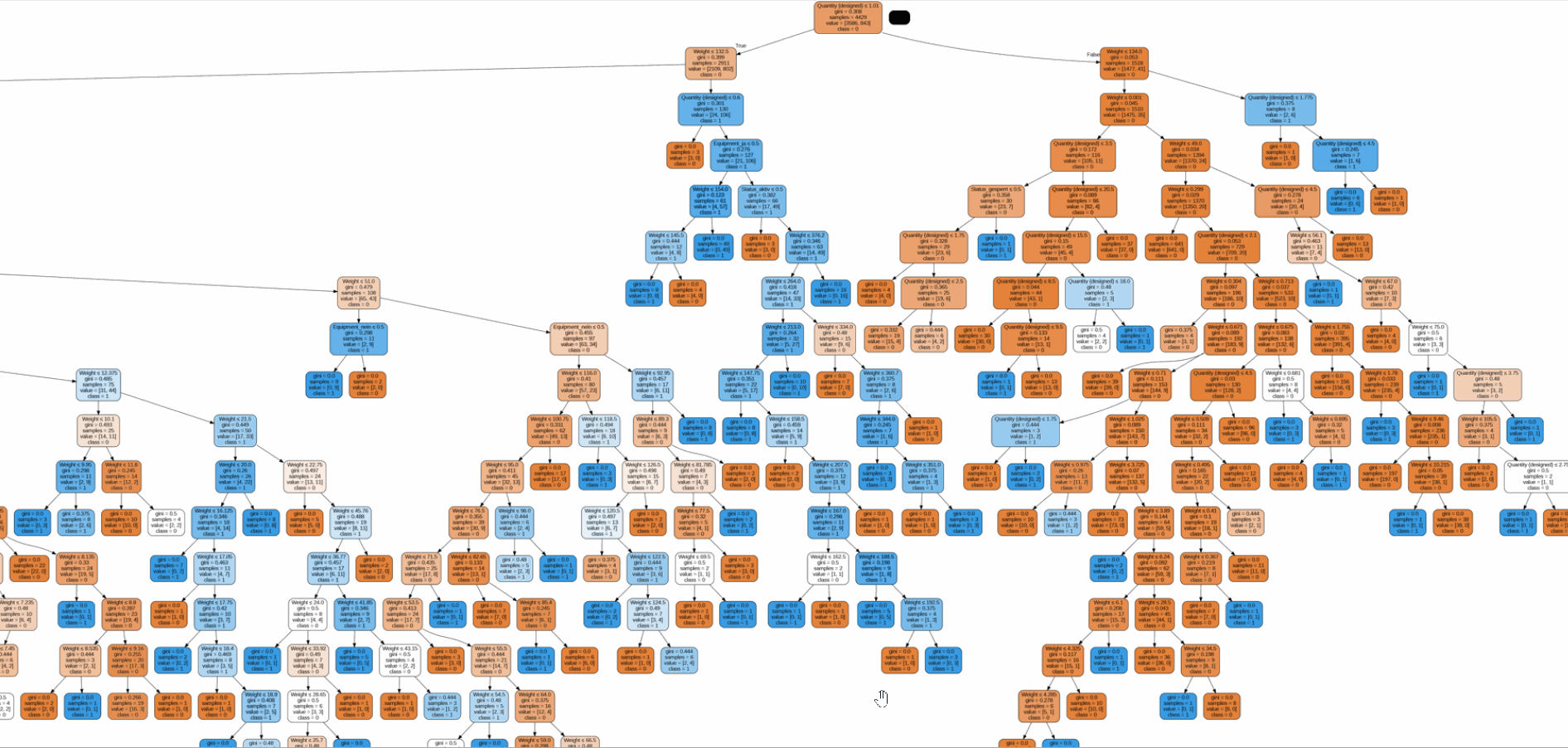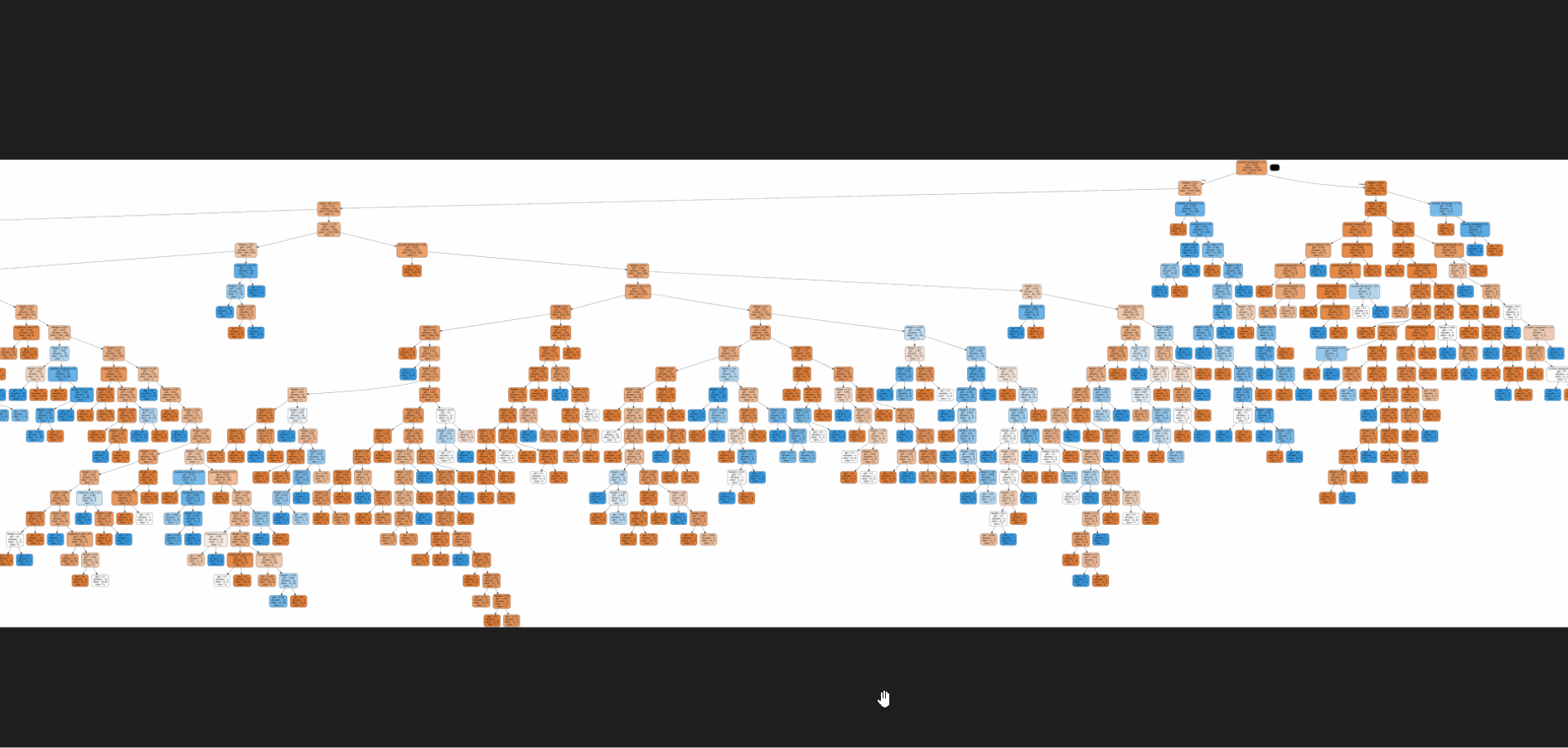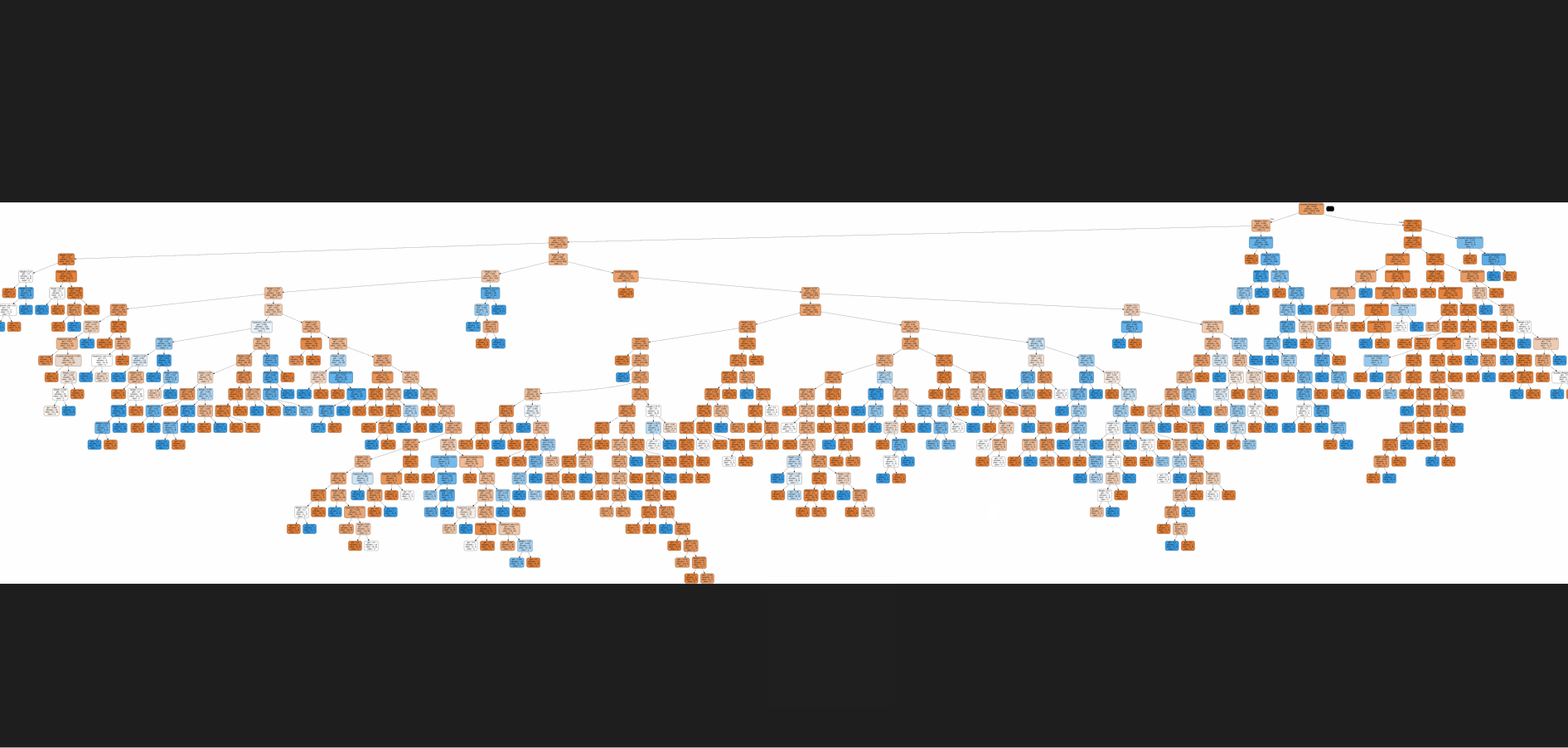
The challenge lies in the sheer volume and complexity of data, which can lead to inaccuracies and inefficiencies, costing time, and resources, and potentially leading to critical errors.
The Impact: Real Cost of Inaccuracy and the Power of AI
The cost of inaccuracies in CI identification can be substantial. Misidentifying a CI could lead to a failure in a critical system, resulting in downtime, loss of productivity, and potential safety risks. Moreover, the time and resources spent on manually identifying CIs and non-CIs in a large BoM can be significant, diverting valuable resources away from other important tasks and increasing the likelihood of human error.
According to a study by McKinsey, AI is expected to lift performance across all industries, especially those with a high share of predictable tasks. AI-enabled work could produce an additional economic production of about $2.6 trillion to $4.4 trillion annually. Predictive maintenance enhanced by AI allows for better prediction and avoidance of machine failure, potentially increasing asset productivity by up to 20% and reducing overall maintenance costs by up to 10%. Depending on the complexity of the task and the efficiency of the AI model, a 20% to 50% reduction in time spent, or even more, is achievable.
Our Approach: The Machine Learning Lifecycle
To tackle above mentioned challenge of identifying Configuration Items in the BoM, we adopted a comprehensive Machine Learning Lifecycle approach. This involved:
Target Identification: Our primary goal was to accurately distinguish between CIs and non-CIs within the BoM. This required a deep understanding of the specific characteristics of CIs and how they differ from non-CIs.
Data Collection, Cleansing, and Processing: We gathered necessary data from the BoM, including information like the article name, quantity, weight, etc. This data was converted into a digestible format for the algorithm and served as the foundation for our machine-learning model.

Word embeddings are dense vector representations that capture semantic and contextual information. By representing words in a continuous vector space, word embeddings enable algorithms to consider the contextual similarities between words.
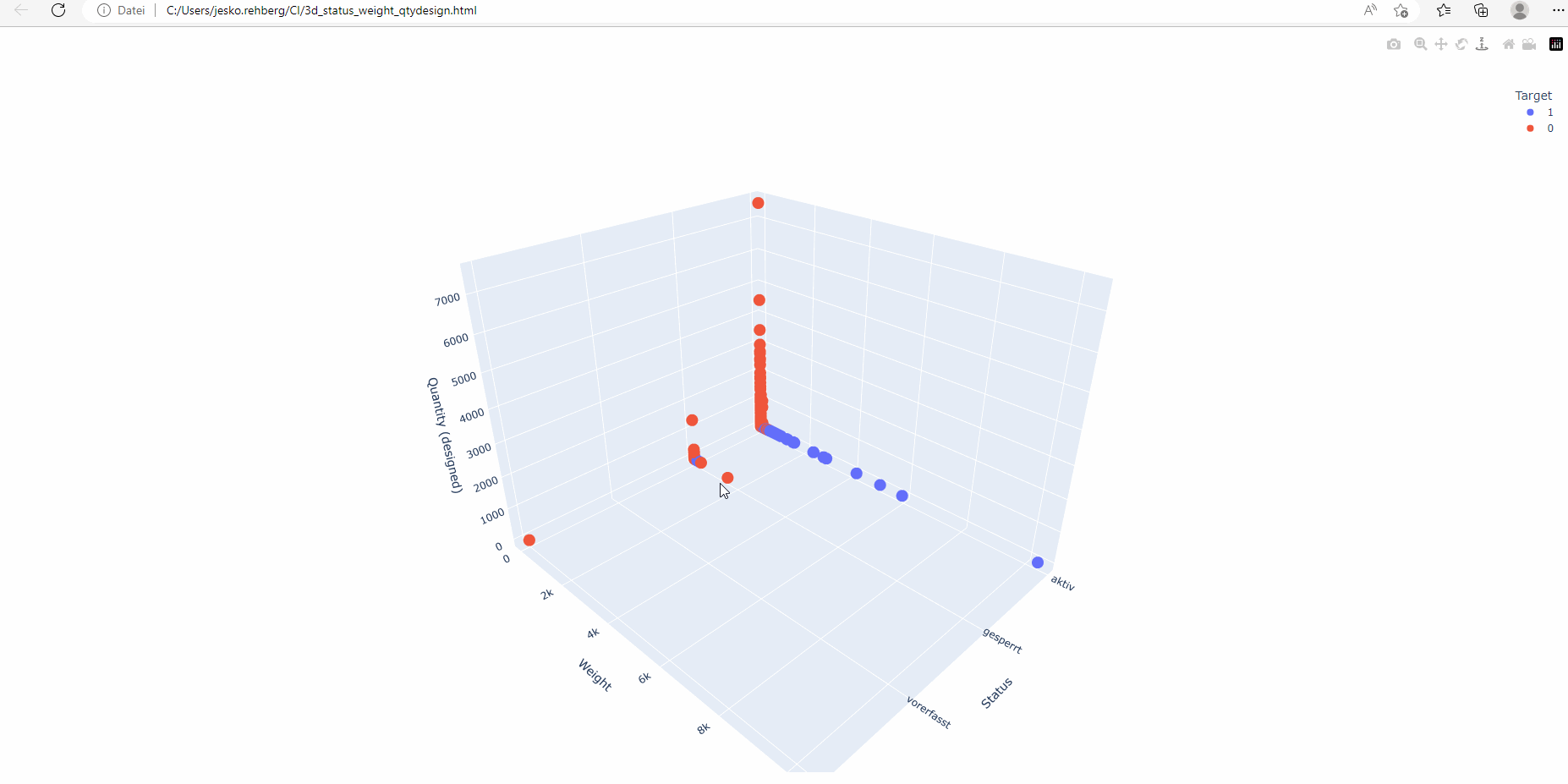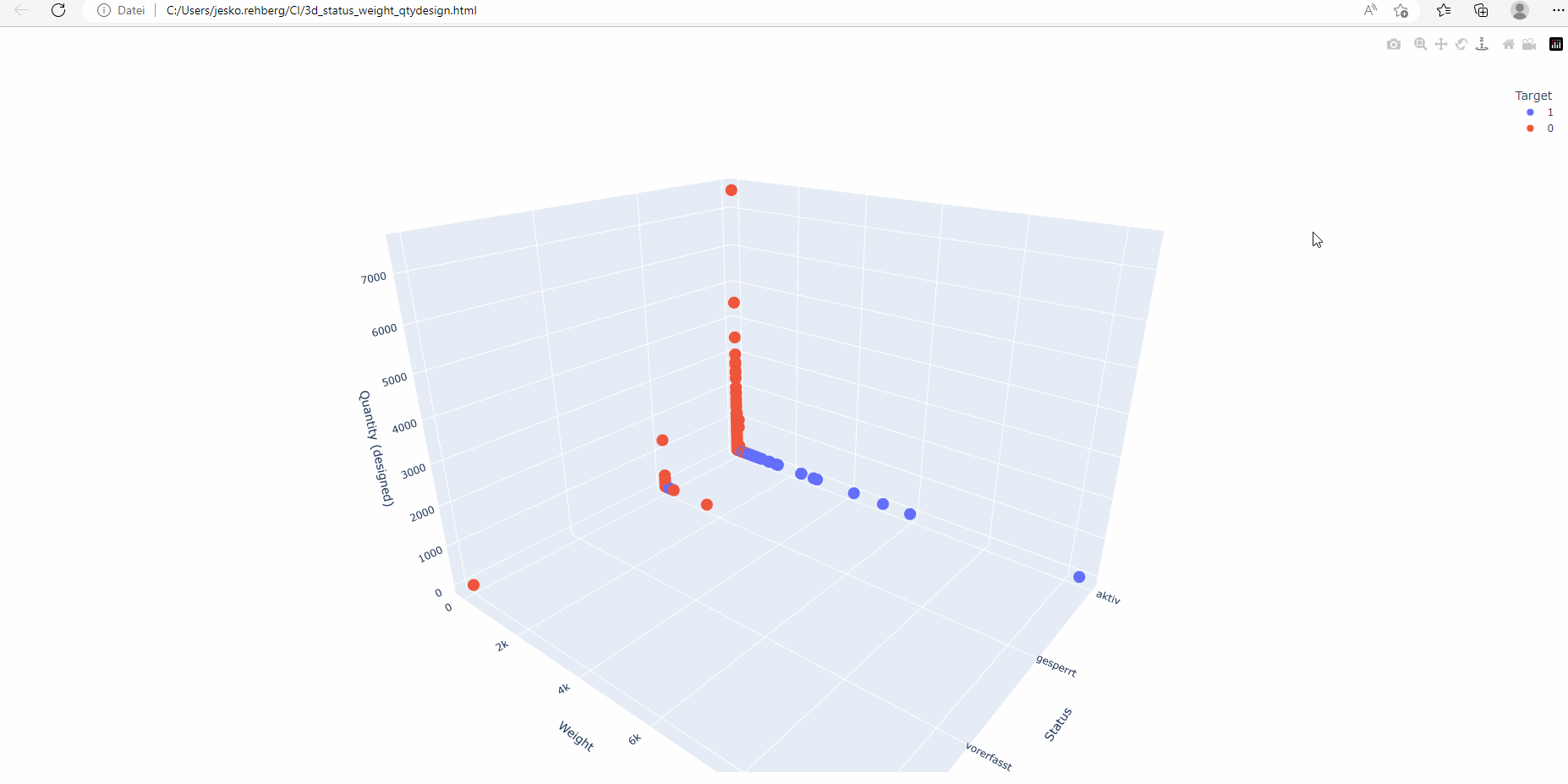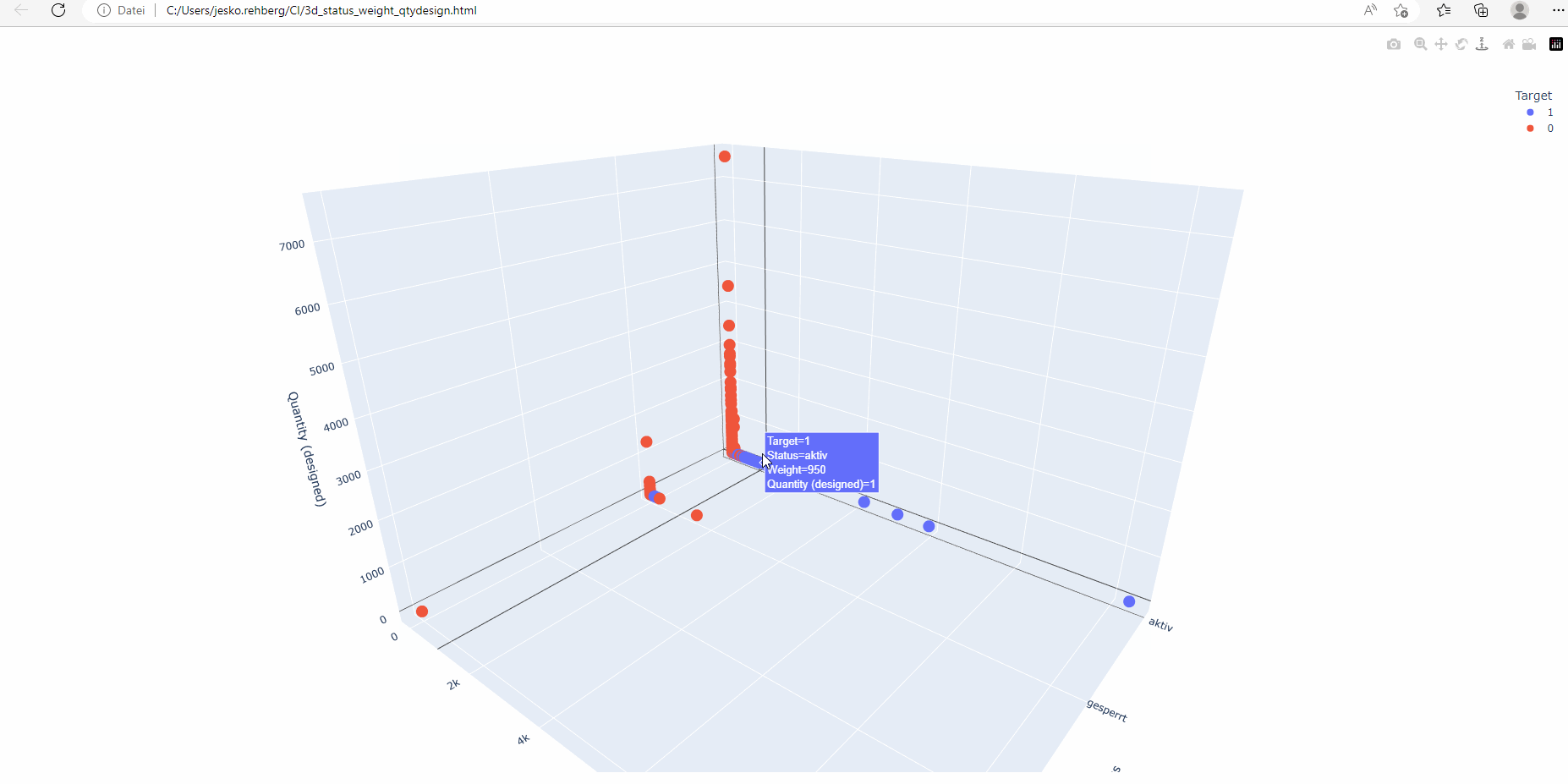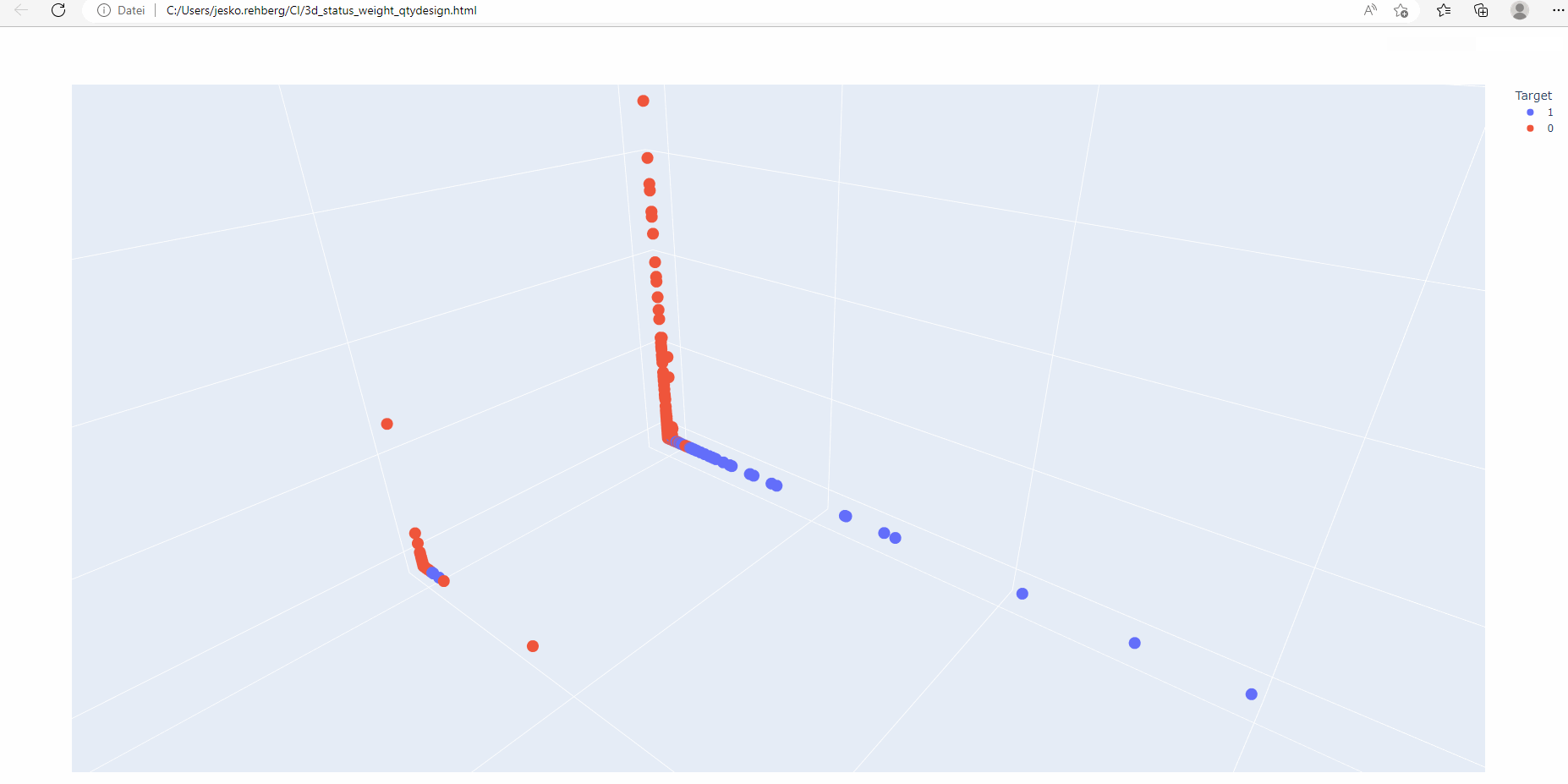
Multi-dimensional plotting is particularly useful when dealing with multiple features. By displaying data points in a 3D space, humans can gain visual insights into the interaction of different variables and their impact on CI classification
Exploratory Data Analysis (EDA): Before diving into model building, we conducted an in-depth EDA. This step involved visualizing the data, identifying outliers, handling missing data, and understanding the underlying patterns and relationships within the data. This process helped us to better understand the structure of our data and guided our subsequent steps.
Model Training and Testing: We utilized word embedding techniques to convert words into numerical vectors in a high-dimensional space. This method allowed us to capture the semantic and syntactic relationships between words, which played a crucial role in identifying CIs and non-CIs. We trained our model on a portion of our data and then tested it on unseen data to evaluate its performance.

Training the model: Training involves feeding the model with input data and corresponding target data in order to optimize its internal parameters and make accurate predictions. During each epoch, the model updates its internal parameters through a process called “backpropagation,” where it computes the loss between its predicted output and the actual target output and adjusts the parameters to minimize this loss using an optimizer
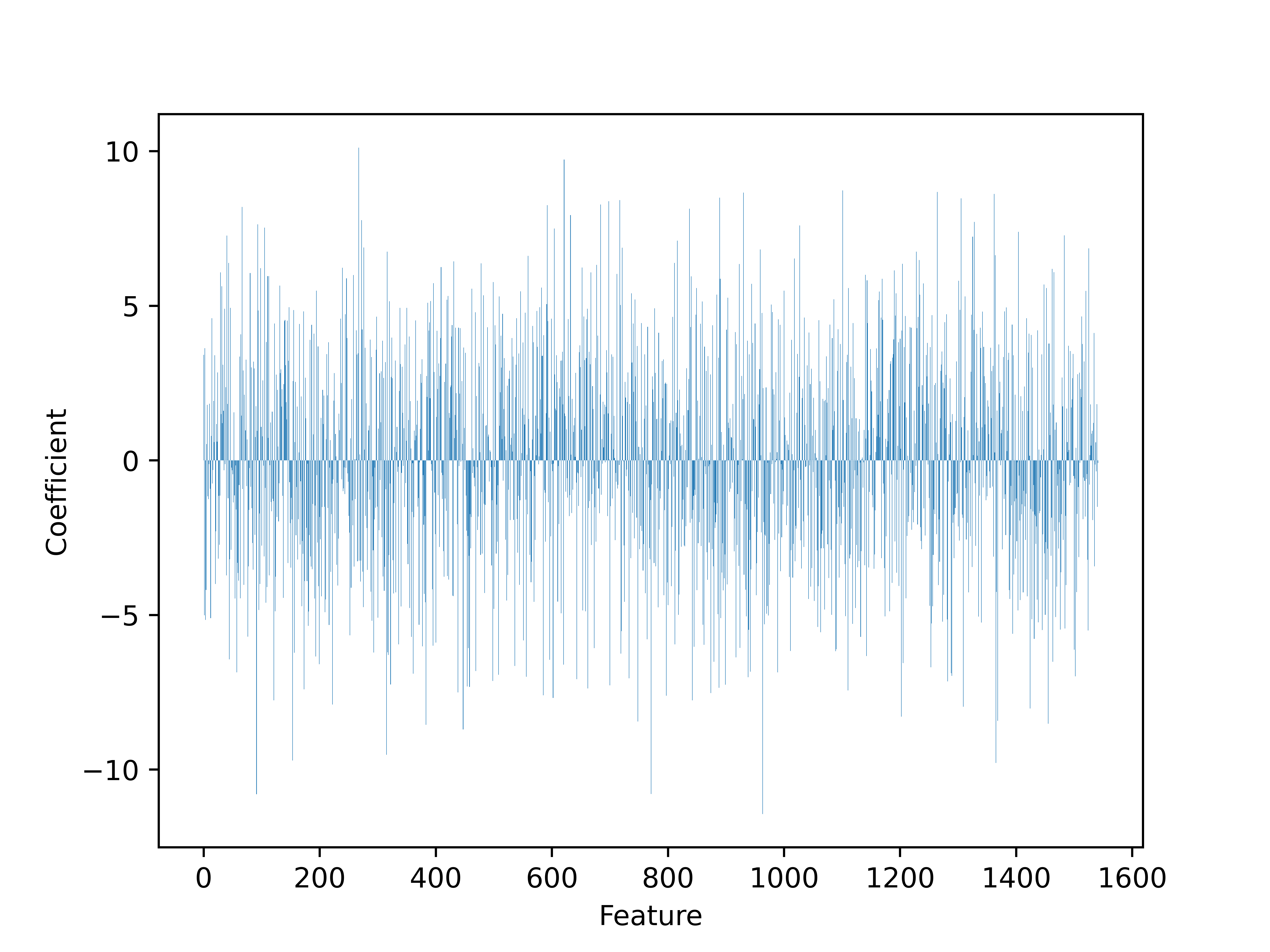
Feature Importance: feature coefficients or weights are assigned to each input feature to indicate the importance of each feature in the model’s decision-making process.
Parameter Tuning and Feature Engineering: After the initial model training and testing, we fine-tuned the model parameters to improve its performance. This involved adjusting various hyperparameters of the model. Additionally, we engineered new features from the existing data to provide more informative inputs to our model. In the graph below, the features are displayed on the x-axis, and the corresponding coefficients are displayed on the y-axis. The most important features are those that have the highest absolute coefficient values, as they have the largest impact on the model’s predictions. To determine which features are most important in the graph, look for the bars that are the tallest (either positive or negative). These represent the features with the highest absolute coefficient values and therefore the greatest impact on the model’s predictions.
Model Evaluation and Optimization: We evaluated the performance of our model using appropriate metrics. In our case, accuracy was a key metric, as our goal was to correctly identify CIs and non-CIs. Based on the evaluation, we further optimized our model to achieve the best possible performance, paying attention to both underfitting and overfitting: It is essential to recognize the potential pitfalls associated with the curse of dimensionality.
Model Deployment: Once we were satisfied with the performance of our model, we deployed it for use. This meant integrating the model into the existing workflow where it could start providing value by accurately identifying CIs and non-CIs in the BoM. The model can be deployed both as a local standalone application as well as in the cloud.
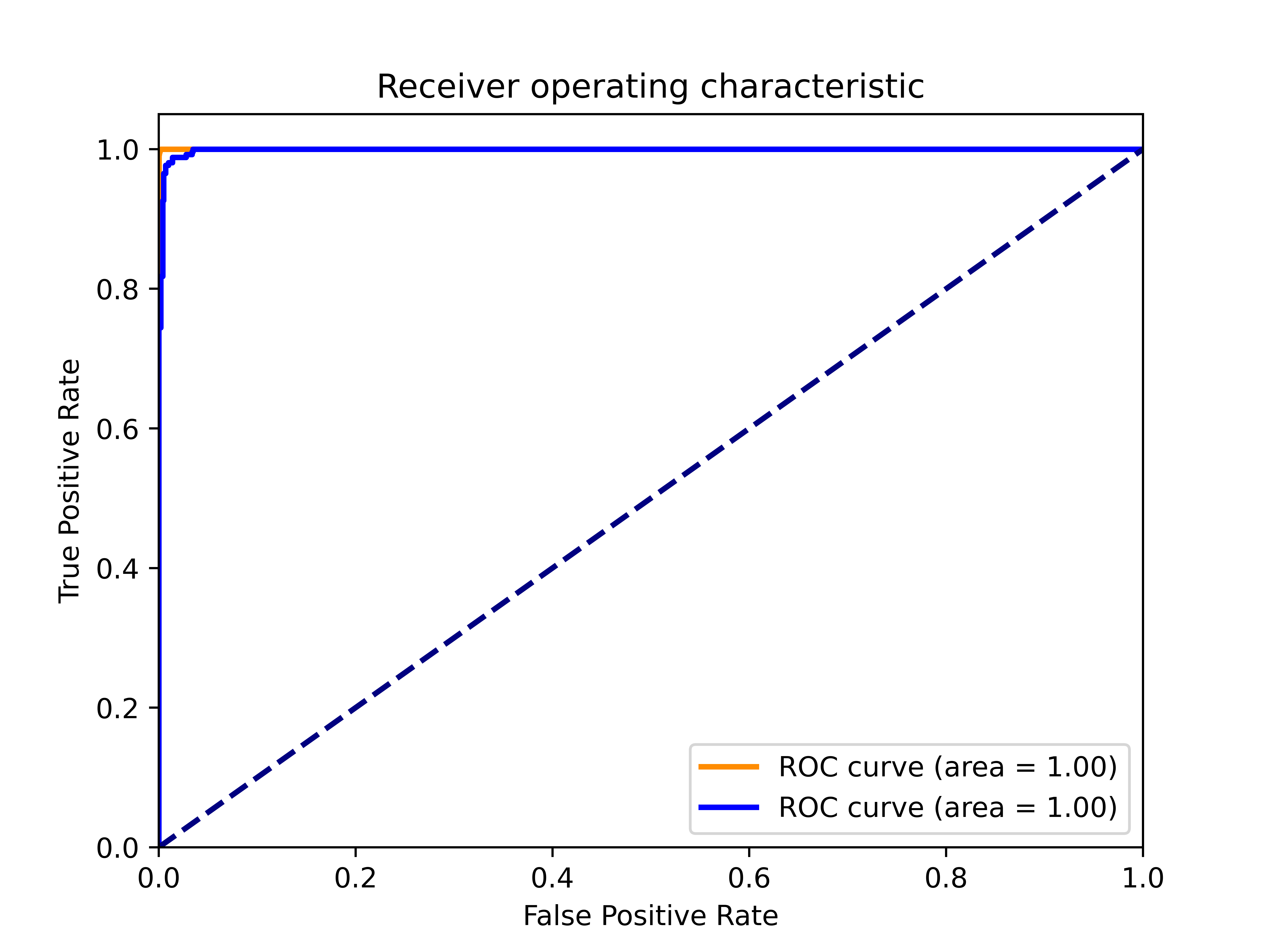
Evaluate performance with Receiver Operating Characteristic (ROC) ROC curve is used to evaluate the performance of the CI classification model. It plots the relationship between the True Positive Rate (TPR) and the False Positive Rate (FPR) at various classification thresholds. The True Positive Rate, also known as sensitivity or recall, represents the proportion of actual positive instances correctly classified as positive by the model. The False Positive Rate, on the other hand, measures the proportion of actual negative instances that are incorrectly classified as positive by the model.
The Result: Harnessing AI for Accurate CI Identification
Our machine learning model was able to accurately identify CIs and non-CIs in a large BoM with an impressive accuracy of 98%. This not only saves time and reduces errors but also provides valuable insights that can drive decision-making.
For the purpose of continuous process optimization, we intend to challenge the model to ongoing evaluation. The human expert will be able to evaluate the model at any time. If it becomes apparent over time that the prediction accuracy of the model is declining due to changes in the general conditions, this will be detected by automatic monitoring. In the interplay of domain and AI expertise, the corresponding adjusting screws are adjusted within the cycle until the prediction quality of the model is within the desired specification again.
Our Decision Trees have grown another (project) branch, metaphorically speaking, during this CI classification task: we can have CI documentation documents searched and answered in natural language. This goes beyond a mere keyword search, as our model captures the context of the question and can also summarize the answer from different documents. The incorporation of human feedback loops in this question-answering system is what sets our approach apart.
Closing the gap: we at digitalsalt always think outside the box and try to offer holistic and sustainable solutions for our customers. By integrating programming, statistics, business intelligence, and AI, we maximize data utility for our clients.
Our recent project is a testament to our innovative approach and our ability to deliver value to our clients. We are excited about the potential of AI and machine learning to solve complex challenges and look forward to continuing to provide innovative, value-added solutions to our clients.
YOUR POINT OF CONTACT
You’d like to know more or require our support?
We look forward to hearing from you!
